认识 Horizon UI · 13/17:平台与集群自检
译自英文原文:Meet Horizon UI · 13/17: Platform & Cluster Introspection。
这是 Meet Horizon UI 系列的第十三篇,也是第三幕 operate it 的最后一篇。前几篇 operate 文章讲的是怎么操作后端:告警、运行时规则、Live Debugger、跨 layer Inspect。这一篇反过来看后端本身:它现在是否健康?实际加载了哪些配置?数据会保留多久?Platform monitoring 下的三个只读页面回答这些问题。这里没有开关,只给排障时需要的事实。
Cluster Status:后端是否健康,哪些端口可用?
Horizon 和 OAP 通信不只走一个通道,Cluster Status 会把每个通道的健康状态分开显示。可以把它看成两个端口的健康视图,外加一个独立探针:
- Query / GraphQL(
:12800):所有 observability 页面都依赖这个端口。它会显示 OAP 版本、服务端时区和时钟(并排展示浏览器时间),以及 OAP 自己的健康评分。这个部分兼容任意 OAP,包括 10.x。 - Admin host(
:17128):operate 功能依赖这个端口。页面会对每个 admin module 做实时探测:直接 GET 功能实际调用的 REST path,并显示它是否可达、启用它的SW_...环境变量,以及它不可用时哪些功能会受影响。这里包括admin-server、receiver-runtime-rule、dsl-debugging、inspect、ui-management。Admin host 随 OAP 11 提供,所以 10.x 后端上不会显示这个面板。 - Zipkin / OTLP(
:9412):这是信息性探针,只影响 Zipkin trace 菜单。这里红了,其他页面仍然正常工作。
三个面板独立轮询;其中一个变红,不会影响另外两个的判断。正因为这样,当 Horizon 里其他地方看起来不对劲时,Cluster Status 是最适合先打开的页面。
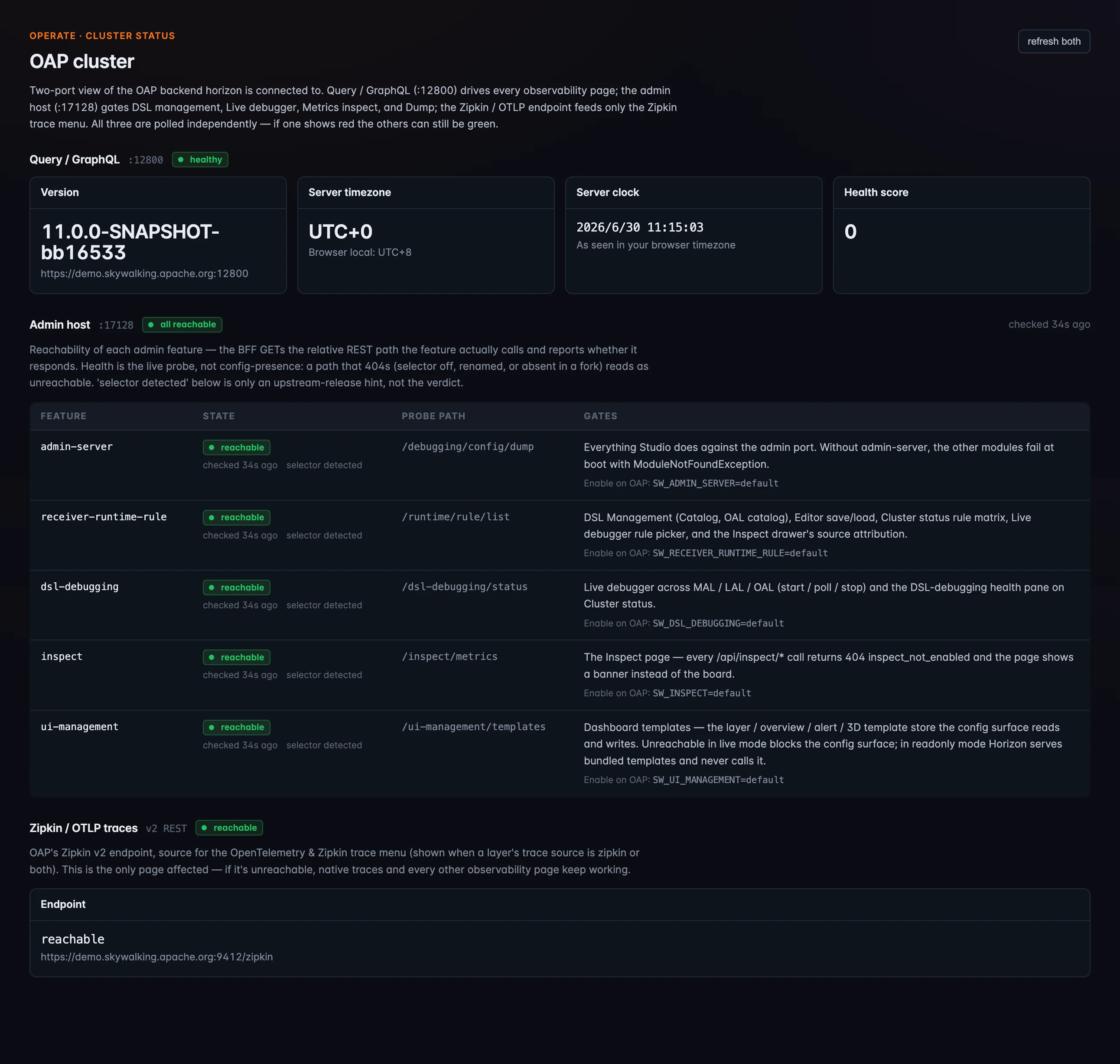 图 1:Cluster Status 是一个双端口健康视图。Query 面板(
图 1:Cluster Status 是一个双端口健康视图。Query 面板(:12800,任意 OAP)显示版本、服务端时间和健康评分;Admin 面板(:17128,OAP 11)用实际 REST path 实时探测每个 admin module,并显示启用它的 SW_... 环境变量和不可达时受影响的功能;Zipkin/OTLP 面板只服务 Zipkin 菜单。
OAP Configuration:实际运行的配置是什么?
当某个配置项表现得和预期不一样,下一步通常是确认:OAP 最终到底解析出了什么配置?OAP Configuration 让你不用 SSH 到后端,也能看到这个答案。它从 admin port 的 /debugging/config/dump 读取当前连接后端的有效运行时配置,按 module 分组,并支持同时搜索 key 和 value。密码、token、access key 这类敏感值会由 OAP 自己在返回前 mask 成 ******,Horizon 看到的就是脱敏后的内容。这个页面严格只读;如果要改配置,仍然需要在 OAP 侧修改并重启。和上面的 Admin 面板一样,它依赖 OAP 11 的 admin host。
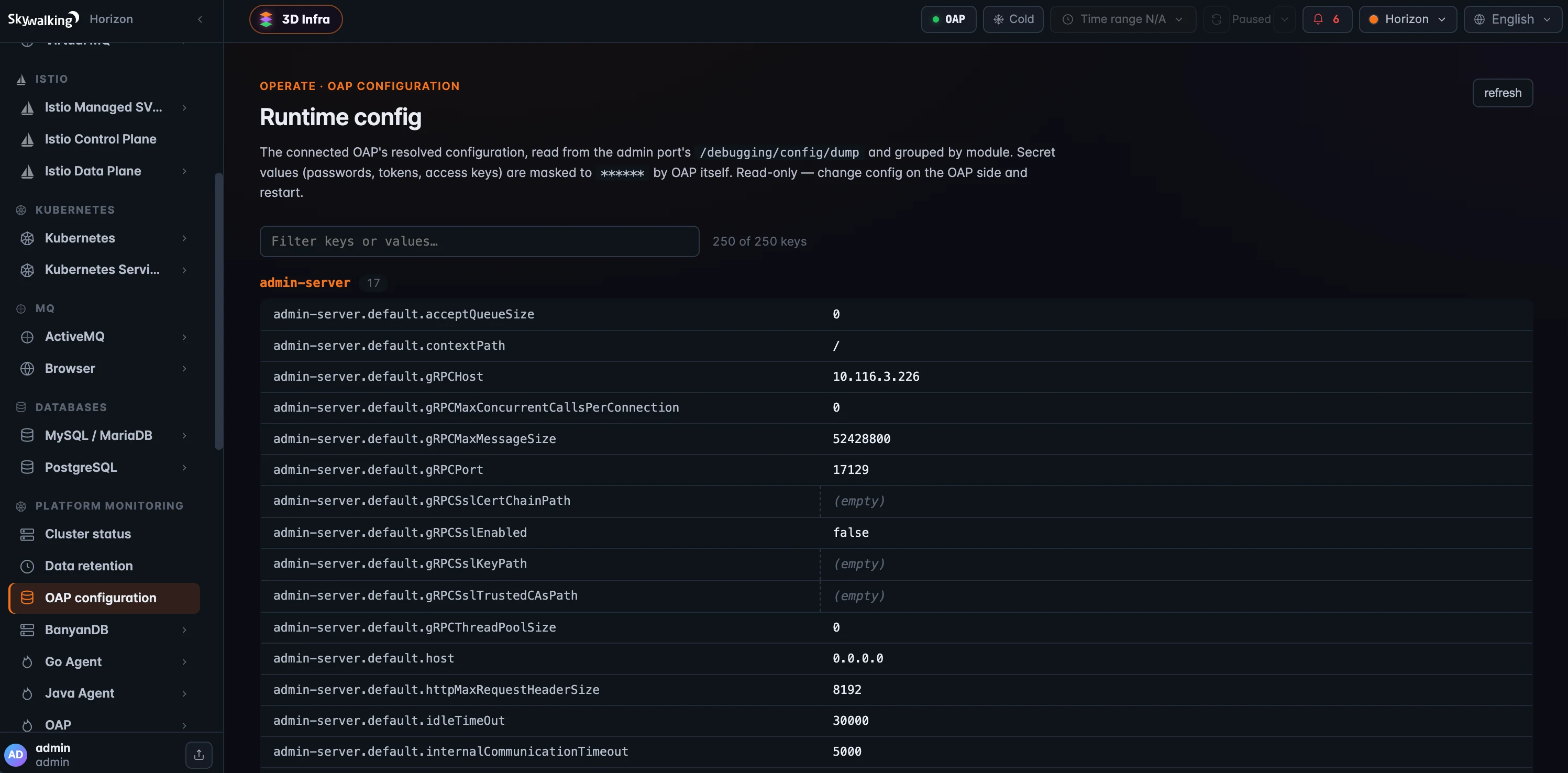 图 2:OAP Configuration 展示当前连接后端解析后的运行时配置,数据来自 admin port;配置按 module 分组,可以过滤,敏感值由 OAP mask 成
图 2:OAP Configuration 展示当前连接后端解析后的运行时配置,数据来自 admin port;配置按 module 分组,可以过滤,敏感值由 OAP mask 成 ******。页面只读:修改配置仍然要在 OAP 侧完成并重启。
Data Retention:数据会保留多久?
Data Retention 展示 OAP 为各类数据设置的 time-to-live,单位是整天:records(trace、log、browser error 等)和 metrics(metadata、minute、hour、day)都会列出来。这里还要看存储后端。像 Elasticsearch 这样的平面存储,每类数据只有一个 retention 数字。在 BanyanDB 中,数据会按可配置的生命周期阶段流转:hot、可选的 warm、可选的 cold。OAP 会把 hot 和 warm 合并报告为一个可查询窗口,所以 Horizon 不再只显示单个数字,而是为每类数据画一条 lifecycle bar:前半段是 hot+warm 窗口,后面接 cold 尾段,宽度按总天数比例展示。这样你可以一眼看出各阶段相对持续多久。
页面还特别提醒一个操作细节:topbar 里的 Cold pill 会把查询切到 cold 数据,它不是把 hot+warm 和 cold 合并查询。所以只有当你要看的时间窗口已经早于 hot+warm 边界时,才值得打开它。Data Retention 走标准 query port,因此不同于前两个页面,它兼容任意 OAP 版本。
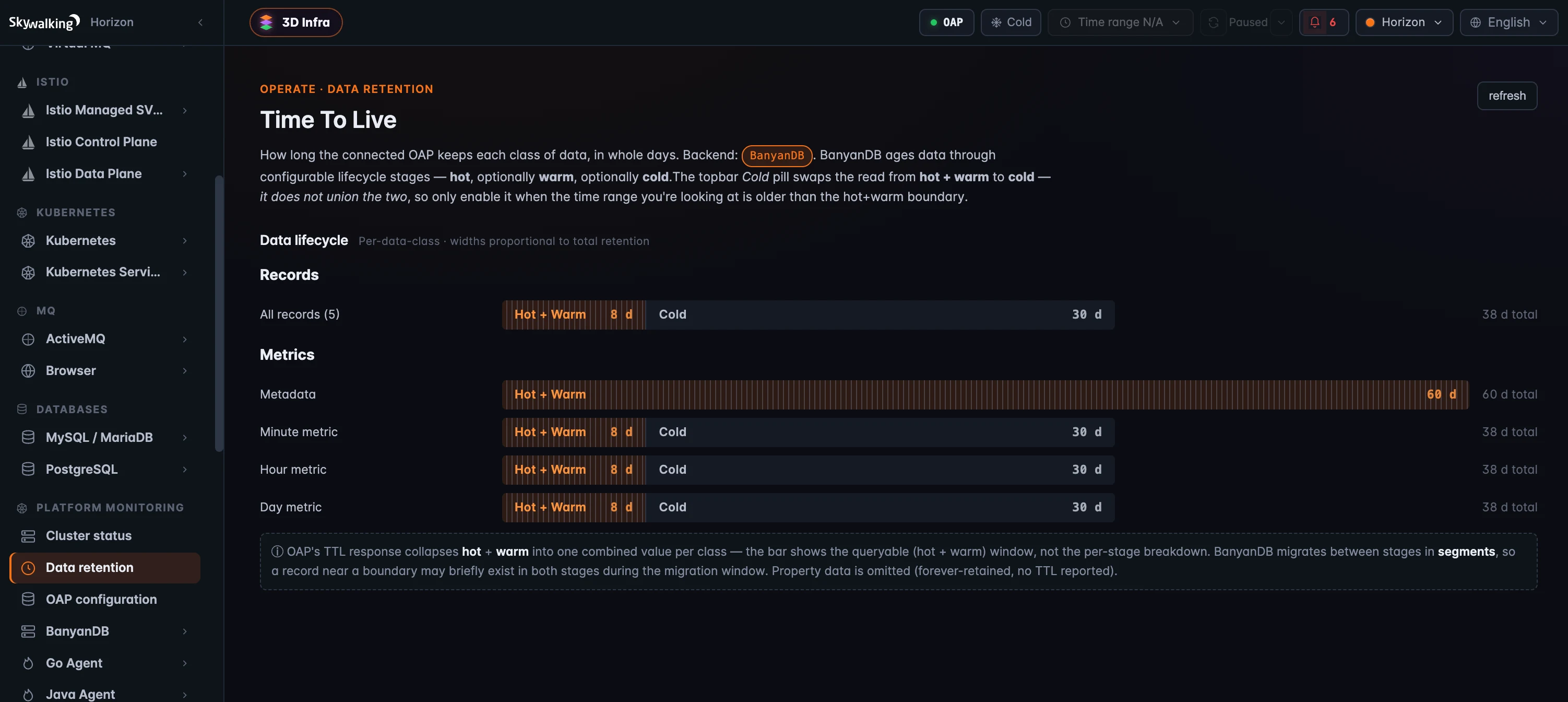 图 3:Data Retention:在 BanyanDB 上,每类数据会经历 hot → warm → cold 生命周期,所以 Horizon 用 lifecycle bar 展示可查询的 hot+warm 窗口和 cold 尾段,宽度按总天数比例计算。平面存储如 Elasticsearch 则会显示每类数据的单个 TTL。
图 3:Data Retention:在 BanyanDB 上,每类数据会经历 hot → warm → cold 生命周期,所以 Horizon 用 lifecycle bar 展示可查询的 hot+warm 窗口和 cold 尾段,宽度按总天数比例计算。平面存储如 Elasticsearch 则会显示每类数据的单个 TTL。
它在哪里运行
这三个页面都在 Platform monitoring 下,各自有独立的读权限:cluster:read、config:read、ttl:read。它们都严格只读:这里做的是自检,不是控制。后端接入方式也延续了 operate 里的分层。Data Retention 和 Cluster Status 的 Query 面板走标准 query port,因此兼容任意 OAP,包括 10.x。Cluster Status 的 Admin 面板和 OAP Configuration 则读取 OAP 11 才提供的 admin host;如果后端没有这个端口,页面会明确说明原因,比如隐藏面板,或者显示“需要 admin host”的提示,而不是直接报错。(这里关注的是平台健康和配置;OAP 自观测的 dashboard 是另一条基于 metrics 的线。)
后续阅读
字段参考,包括每个面板、config dump 结构和 BanyanDB 生命周期细节,可以看 Cluster Status、OAP Configuration 和 Data Retention 文档。
到这里,Act 3 — operate it 结束。下一篇:访问控制与安全,进入 Act 4 — govern & secure it:服务端强制执行的 RBAC、LDAP/AD、audit log,以及 break-glass。