认识 Horizon UI · 9/17:五种 Profiler,一套火焰图
译自英文原文:Meet Horizon UI · 9/17: Five Profilers, One Flame Graph。
这是 Meet Horizon UI 系列的第九篇。指标告诉你 什么 变慢了;Trace 告诉你慢在哪一跳;Profiling 再往下一层,进入运行中服务的调用栈、内核事件和进程间通信,告诉你问题落在 哪段代码。SkyWalking 为这件事提供了五种 profiler,Horizon 会把它们都展示出来。这篇的主线是:五种里有四种进入同一套火焰图,第五种则是刻意设计的例外。
一个渲染器,四种 profiler
Trace、async、eBPF 和 pprof 这四类 profiling 最终都会产出同一类数据:一棵带采样计数的 stack frame 树。Horizon 先把它们归一成同一种结构,再交给 同一个火焰图组件(基于 d3-flame-graph 封装)渲染。好处很直接:你只需要学一次这个视图,之后四种 profiling 都按同样方式读:
- 每个 frame 的宽度代表它占全部样本的比例;hover 卡片会显示代码签名、dump 次数、耗时(包含和 不包含 子调用),以及该 frame 占根节点的 % of root;
- 点击一个 frame 会缩放进去,并把选中高亮固定住;这个选中态在四种 profiler 里保持一致;
- 每个 frame 使用由方法名决定的低饱和度颜色,让上千个 frame 的图在暗色画布上仍然能读。
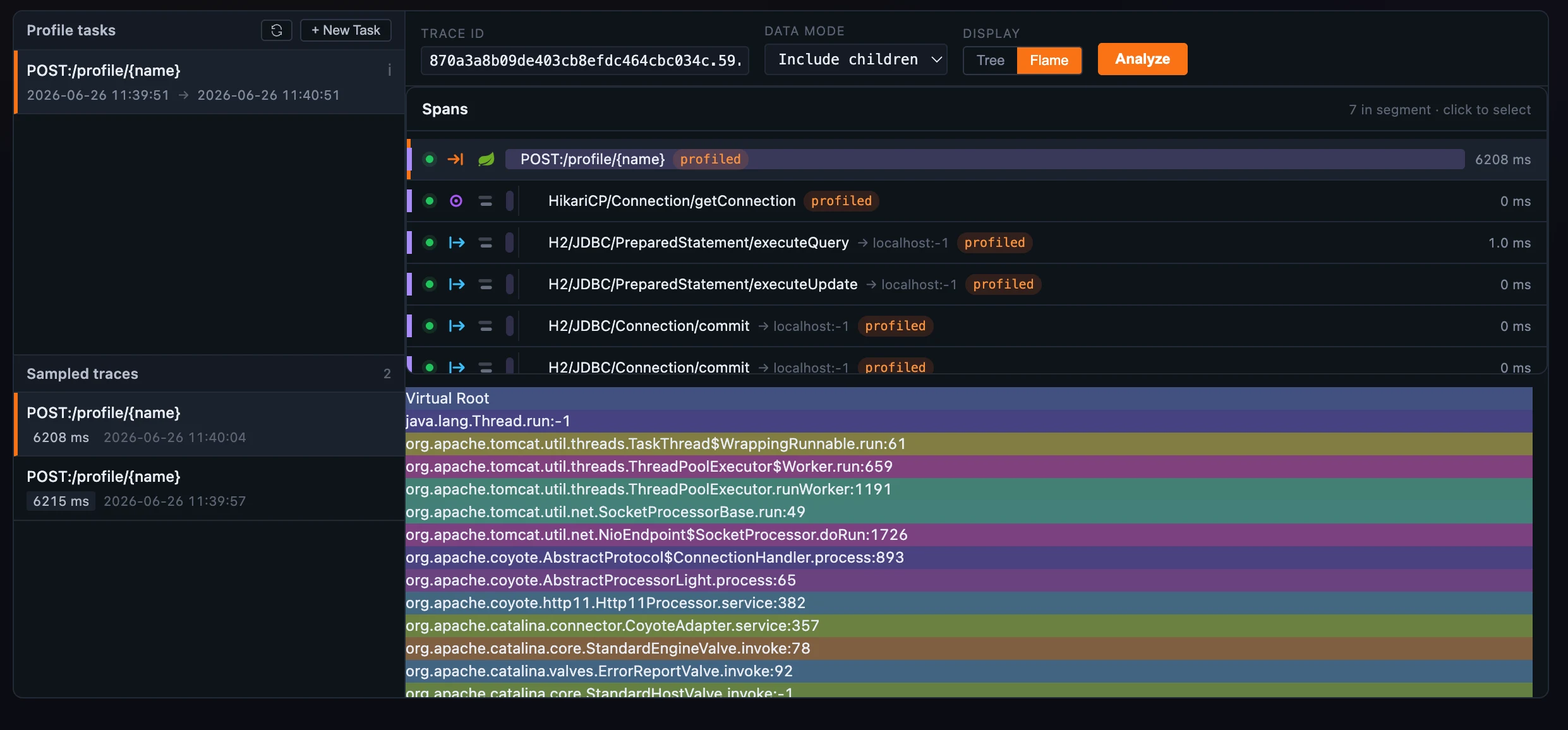 图 1:四种 profiler 共用一套火焰图:frame 按样本占比展开,选中 frame 会固定高亮,hover 卡片显示 % of root。
图 1:四种 profiler 共用一套火焰图:frame 按样本占比展开,选中 frame 会固定高亮,hover 卡片显示 % of root。
在 Trace 和 eBPF 标签页里,同一份分析结果还可以切到 Tree 视图:它是一张缩进的 stack 表,逐帧展示每个方法的 total 和 self duration,以及 dump count。(Async 和 pprof 只提供火焰图;只有同时支持两种视图的地方才会出现这个切换。)
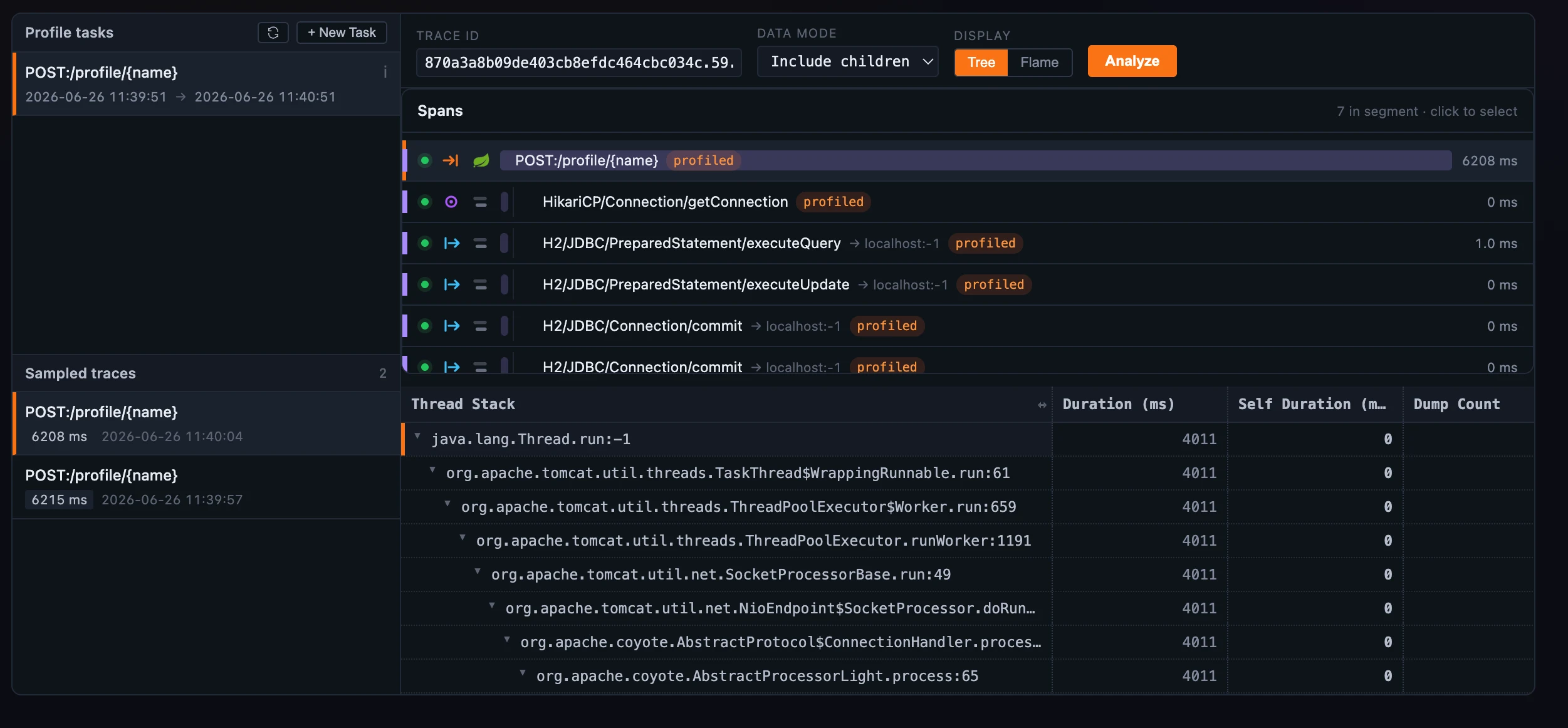 图 2:同一份结果,一次切换即可从火焰图变成 Tree:缩进 stack 表展示 total/self duration 和 dump count。
图 2:同一份结果,一次切换即可从火焰图变成 Tree:缩进 stack 表展示 total/self duration 和 dump count。
四种 stack profiler 分别抓什么
这四种 stack profiler 共用渲染器,但回答的问题不同,每种也有自己的 New Task 表单:
- Trace Profiling 会对 慢 trace segment 的调用栈采样。创建任务时指定 service(也可以限定 endpoint)、慢调用 threshold 和 dump period。segment 超过阈值时,agent 会抓取线程栈快照。之后你选择一条采样到的 Trace,下钻到带 profiling 的 span,再点 Analyze。这里还有一个 data mode,可以选择是否把 child span 时间计入结果。
- Async Profiling 在运行中的 Java 服务上启动 JVM async-profiler,不需要重启。一个任务可以同时覆盖多个实例和多个事件:
CPU、ALLOC、LOCK、WALL以及 timer 类事件。选择不同 event type 后,火焰图会按对应事件重新绘制。 - eBPF Profiling 不需要进程内 agent,由 SkyWalking Rover 在内核层抓 stack:ON_CPU 看进程把 CPU 花在哪里,OFF_CPU 看它阻塞在哪里,比如锁、I/O、调度。进程选择器可以展开进程属性,固定要剖析的进程;聚合开关可以选择统计样本数,或者累加 blocked time(后者只适合 off-CPU)。
- pprof 通过 Go 标准 runtime profiler 剖析运行中的 Go 服务。每个任务只能选择 一个 event,来自
CPU、HEAP、BLOCK、MUTEX、GOROUTINE、ALLOCS和THREADCREATE。对话框会跟随 event 调整:定时采集需要 duration,BLOCK/MUTEX需要 sampling rate,其余则是一次性快照。
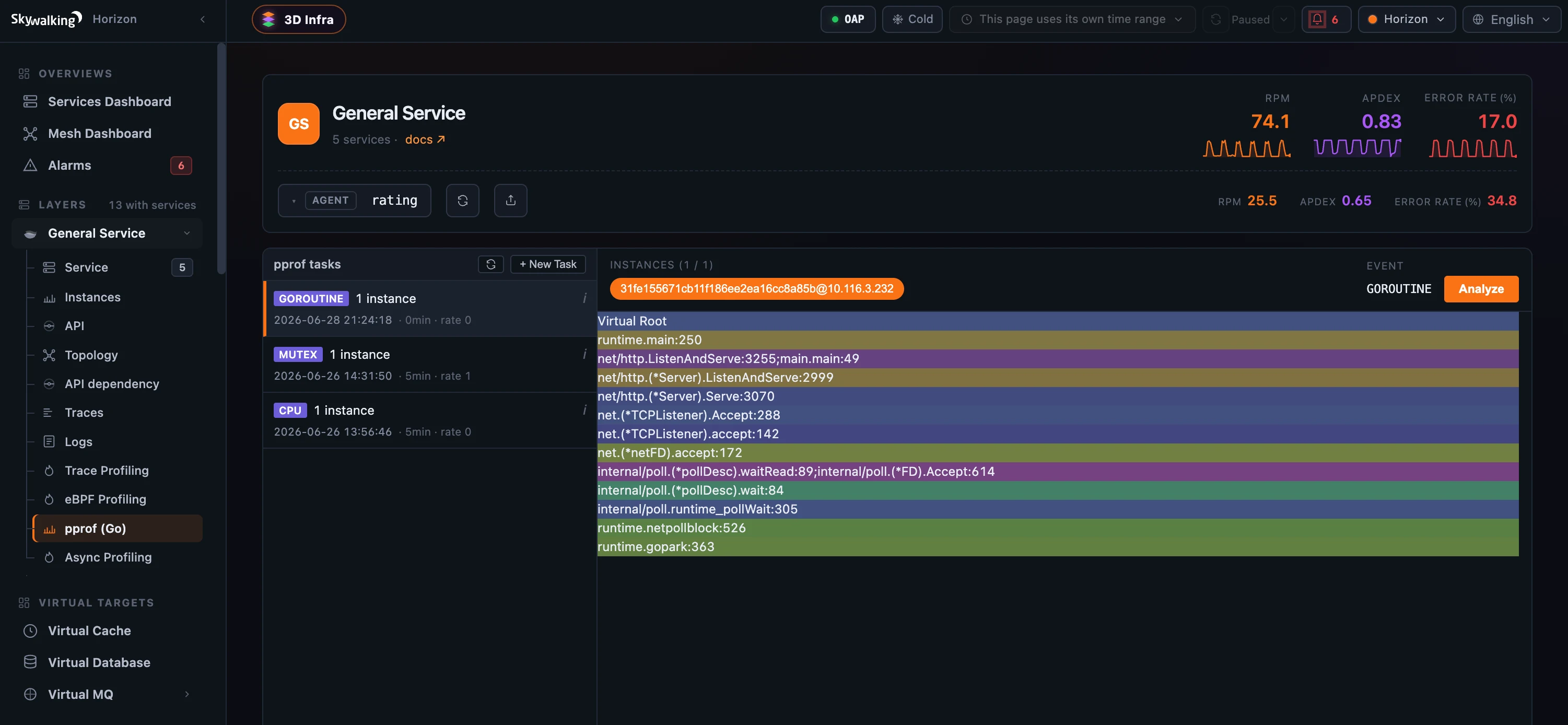 图 3:pprof 每个任务只采一个 Go event:GOROUTINE、MUTEX 和 CPU 是不同任务,各自带 duration 和 sampling rate;选中后 Analyze,同样进入火焰图。
图 3:pprof 每个任务只采一个 Go event:GOROUTINE、MUTEX 和 CPU 是不同任务,各自带 duration 和 sampling rate;选中后 Analyze,同样进入火焰图。
Network Profiling:刻意设计的例外
第五种 profiler 问的是另一类问题:不是“一个进程把时间花在哪里”,而是“哪些进程在通信、通过什么协议通信”。所以它刻意不用火焰图。Network Profiling 会捕获某个服务实例内进程之间的网络会话,并画成 蜂窝拓扑:每个进程是一个六边形,实例自身的进程聚在虚线 pod 边界内,外部 peers 围在边缘。它们之间的边有方向、有动画,并按协议着色:HTTPS、TLS、HTTP 和普通 TCP 都有自己的颜色和小标签。
它的运行方式也不同:network task 不是固定时长,而是带 sampling rules。你可以按 URI pattern、4xx/5xx 响应或最小时延匹配,并配置保留多少 request/response body。任务会一直运行,直到你手动停止。点击一条边,会打开 Client side | Server side 面板,展示这段会话在当前窗口内的调用速率、时延和字节数图表。它使用的是和 3D Infrastructure Map 同源的 process-relation 数据。这里看不到火焰图,这正是设计。
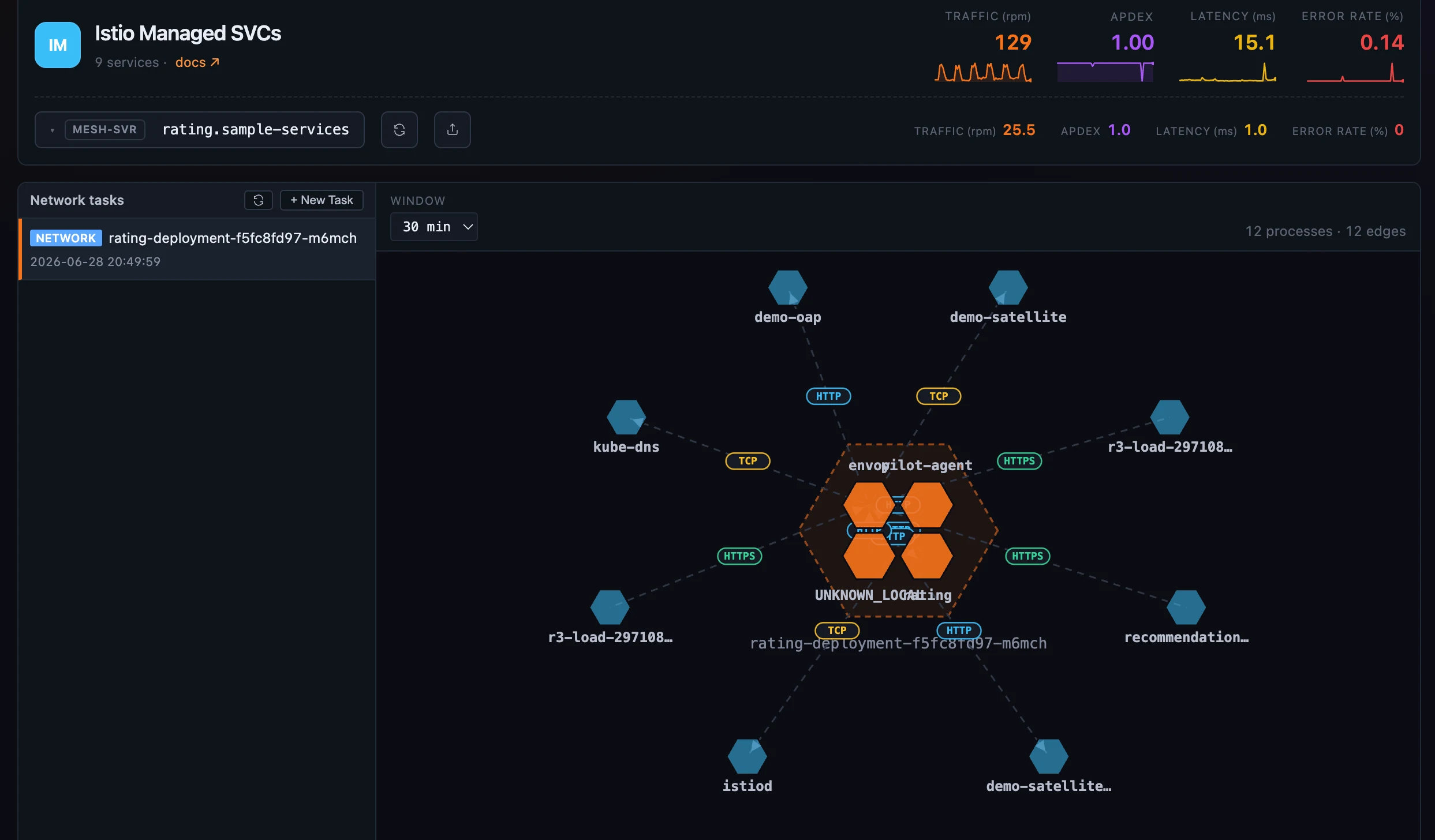 图 4:这个 profiler 是例外:进程通信画成蜂窝拓扑。pod 内进程聚在虚线边界内,外部 peers 围在外侧,每条边按协议着色;点击边会打开 client-vs-server 指标。
图 4:这个 profiler 是例外:进程通信画成蜂窝拓扑。pod 内进程聚在虚线边界内,外部 peers 围在外侧,每条边按协议着色;点击边会打开 client-vs-server 指标。
同一套任务模型,两类权限
虽然五种 profiler 抓取的内容不同,每个 profiling 标签页的操作流程是一样的:左侧是 任务列表,上方有 New Task,右侧是 结果面板。创建任务后,列表会轮询几轮,等待 OAP 下发任务、实例回报结果;选中一个任务后再分析。
创建任务和读取结果也是一条权限边界。启动任务需要 profile:enable(默认 operator 及以上拥有),因为没有边界的 profile 可能把生产实例 CPU 打满,所以任务表单的时长和数据大小都在服务端限额。读取 结果只需要 profile:read(属于只读数据权限)。所以 viewer 可以一直看火焰图,但不能发起 profiling 任务。
你能看到哪些标签页,也取决于当前服务:只有 OAP 上报该服务支持某类 profiling 时,对应标签页才会出现。实际使用中,General agent Layer 会带上四个 stack 引擎(trace、eBPF、async、pprof);部署了 Rover 的地方会有 eBPF;service mesh 上会出现 network profiling。
后续阅读
字段参考,包括每个任务字段、eBPF 聚合模式和 network sampling rules,可以看 Profiling 文档。
下一篇:告警与 Incident 排查:Horizon 如何把重复告警归并成 incident,并回放触发规则时的 MQE 指标快照。